
来源:华泰睿思
核心观点
DeepSeek于5月28日更新了R1-0528模型,并于5月29日发布官方更新说明。R1-0528与旧版R1相比,在官方列举的数学和代码等领域,实现了性能15%-26%的较大提升。与海外模型相比,R1-0528各项性能接近OpenAI的o3模型,与Google Gemini 2.5 Pro相比性能各有高低。我们认为,除了性能的提升外,更重要的变化是R1-0528开始支持工具调用,而工具调用是构建Agent的必备属性。R1-0528有望在Agent领域展开探索,有望打破目前Manus、Genspark依赖海外模型(Anthropic Claude)当做核心模型的现状。标的方面仍然聚焦Agent和MCP方向。
R1-0528与旧版本使用相同基础模型,仅靠后训练Scaling Law提效
DeepSeek官方指出,R1-0528的基座模型还是去年12月发布的DeepSeek-V3,与R1旧版本保持一致。今年3月更新的V3-0324并未在R1-0528中使用。模型能力提升仍然是依赖后训练Scaling Law,即在后训练过程中投入了更多算力,显著提升了模型的思维深度与推理能力。用户端显著的变化是模型思考的长度更长,例如旧版R1解答AIME 2025测试集上平均每题使用12K tokens,而新版模型平均每题使用23K tokens。我们认为,2025年后训练Scaling Law将持续有效,各模型厂商还会继续跟进。
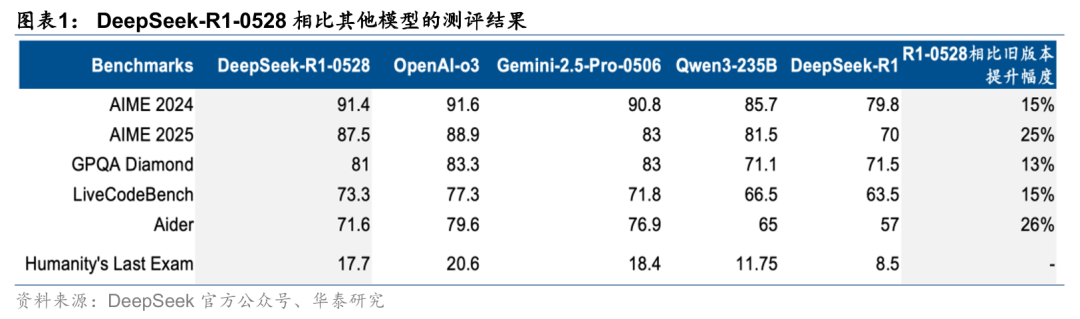
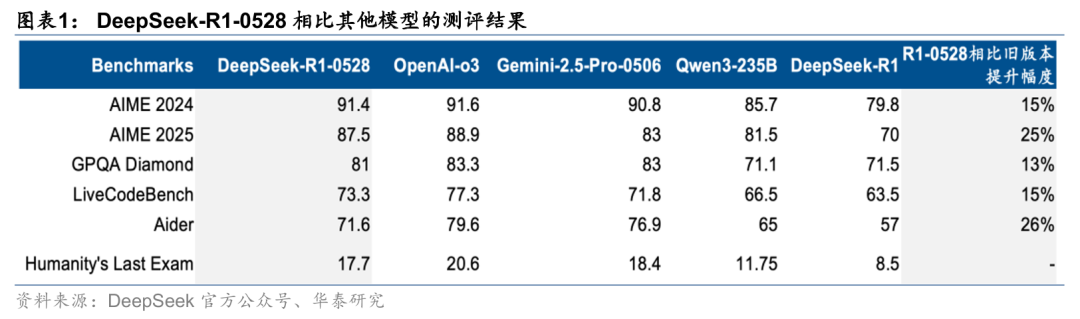
“小更新”并不小,相比前代模型在各项指标上有15-26%的提升
虽然DeepSeek官方表示为“小版本升级”,但我们能看到性能提升幅度还是比较显著的。R1-0528和前一代R1相比,在各项指标上有15-26%提升。与海外头部模型相比,数学、代码、推理等各项性能接近但未超过o3,在部分测评集上强于Google Gemini-2.5- Pro-0506。另外,针对旧版本R1幻觉率高的问题,本次优化后,R1-0528幻觉率降低了45-50%。
工具调用是最大亮点,模型蒸馏继续奏效
DeepSeek官方表述,R1-0528支持工具调用(但不支持在thinking中进行工具调用),在Tau-Bench测评集上与OpenAI o1-high相当,与o3-High和Claude 4 Sonnet仍有差距。由于工具调用是Agent的重要必备条件,鉴于R1的开源性质,我们认为R1-0528有可能被Agent开发者广泛用于复杂Agent流程编排,拓展DeepSeek模型更广泛的使用场景。此外,R1-0528蒸馏的Qwen3-8B在数学性能上有了进一步提高,我们认为利好端侧模型的进步和部署。
投资建议
思路上,我们看好R1-0528带来的Agent潜在推动,结合MCP(模型上下文协议)的广泛普及,进行标的推荐,具体名单请见研报原文。
风险提示:AI技术迭代不及预期,AI商业化不及预期。
相关研报
研报:《DS-R1更新,实现15%以上性能提升》2025年5月30日
站长:乡村生活网;联系电话:023-72261733 ;微信/手机:18996816733;邮箱:2386489682@qq.com;
办公地址:涪陵区松翠路23号附12;


